DAQA - Preliminary analysis#
This is an exploratory data analysis of collected data from DAQA with a focus on people, education affliation and organisations. The work presented below form part of ACDE’s presentation at Data Futures for Architectural History and Cultural Heritage, a collaborative workshop held in November 2022 with DAQA and Curtin University Library. This analysis was followed up with a more detailled analysis which can found in the following page, DAQA: Extended Analysis.
First, we display the number of records for each entity as per the ACDEA.
Show code cell source
# for data mgmt
import json
import pandas as pd
import numpy as np
from collections import Counter
from datetime import datetime
import requests, gzip, io, os, json
import ast
# for plotting
import matplotlib.pyplot as plt
import plotly.graph_objects as go
import seaborn as sns
from matplotlib.colors import to_rgba
# for hypothesis testing
from scipy.stats import chi2_contingency
from scipy.stats import pareto
import warnings
warnings.filterwarnings("ignore")
# provide folder_name which contains uncompressed data i.e., csv and jsonl files
# only need to change this if you have already downloaded data
# otherwise data will be fetched from google drive
global folder_name
folder_name = 'data/local'
def fetch_small_data_from_github(fname):
url = f"https://raw.githubusercontent.com/acd-engine/jupyterbook/master/data/analysis/{fname}"
response = requests.get(url)
rawdata = response.content.decode('utf-8')
return pd.read_csv(io.StringIO(rawdata))
def fetch_date_suffix():
url = f"https://raw.githubusercontent.com/acd-engine/jupyterbook/master/data/analysis/date_suffix"
response = requests.get(url)
rawdata = response.content.decode('utf-8')
try: return rawdata[:12]
except: return None
def check_if_csv_exists_in_folder(filename):
try: return pd.read_csv(os.path.join(folder_name, filename), low_memory=False)
except: return None
def fetch_data(filetype='csv', acdedata='organization'):
filename = f'acde_{acdedata}_{fetch_date_suffix()}.{filetype}'
# first check if the data exists in current directory
data_from_path = check_if_csv_exists_in_folder(filename)
if data_from_path is not None: return data_from_path
urls = fetch_small_data_from_github('acde_data_gdrive_urls.csv')
sharelink = urls[urls.data == acdedata][filetype].values[0]
url = f'https://drive.google.com/u/0/uc?id={sharelink}&export=download&confirm=yes'
response = requests.get(url)
decompressed_data = gzip.decompress(response.content)
decompressed_buffer = io.StringIO(decompressed_data.decode('utf-8'))
try:
if filetype == 'csv': df = pd.read_csv(decompressed_buffer, low_memory=False)
else: df = [json.loads(jl) for jl in pd.read_json(decompressed_buffer, lines=True, orient='records')[0]]
return pd.DataFrame(df)
except: return None
def fetch_all_DAQA_data():
daqa_data_dict = dict()
for entity in ['event', 'organization', 'person', 'place', 'recognition', 'resource', 'work']:
daqa_this_entity = fetch_data(acdedata=entity)
daqa_data_dict[entity] = daqa_this_entity[daqa_this_entity.data_source.str.contains('DAQA')]
return daqa_data_dict
df_daqa_dict = fetch_all_DAQA_data() # 1 min if data is already downloaded
Show code cell source
# print number of records for each entity
print('Number of records for each entity in DAQA dataset')
print('_________________________________________________\n')
for k,v in df_daqa_dict.items(): print(k + ':',len(v))
Number of records for each entity in DAQA dataset
_________________________________________________
event: 0
organization: 967
person: 1103
place: 1939
recognition: 27
resource: 7696
work: 2203
DAQA Persons#
There are 1103 person records in DAQA. The following bar charts show the proportion of certain characteristics of persons in DAQA. We list the main findings below:
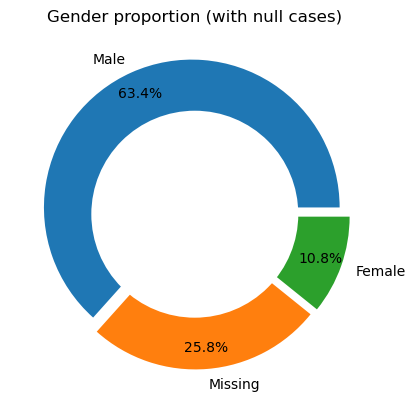
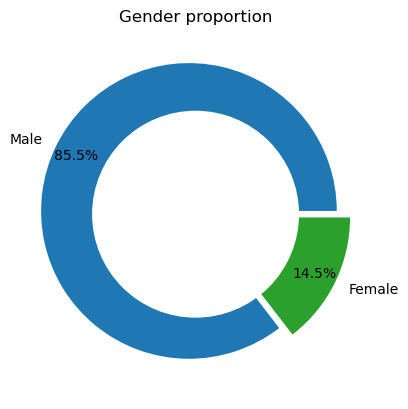
When we consider
nullcases, we find that males make up almost two-thirds of the persons records.Without null cases, we see a male-to-female ratio of 85:15.
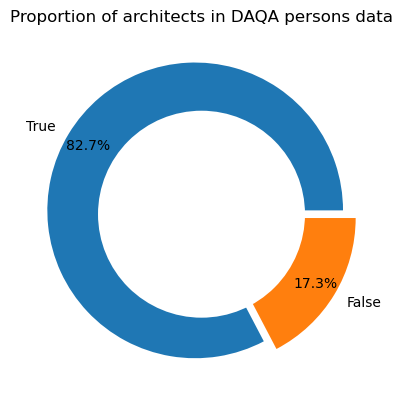
Out of the 1103 persons, 912 are architects making up 83% of the total persons records.
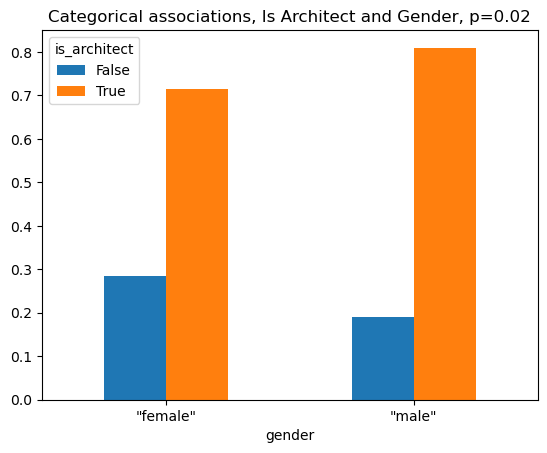
We check for any categorical associations between gender and whether a person is an architect. Using a chi-square test of association, we find statistically significant results with a p-value of 0.02. This suggests that these two variables are not independent of each other, and that more males tend to be architects than females.
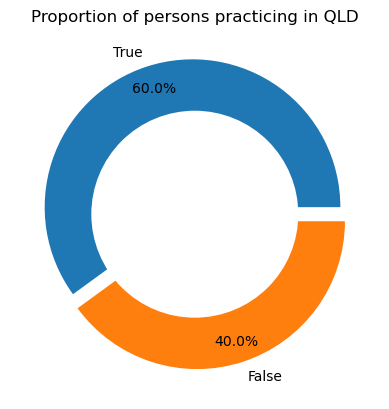
Lastly, we find that 60% of the persons recorded in DAQA practiced in Queensland.
Show code cell source
## Gender Proportion
df_gender=pd.DataFrame(dict(Counter(df_daqa_dict['person']["gender"])).items(),
columns=["Gender","Frequency"])
# explosion
explode = (0.05, 0.05, 0.05)
# Pie Chart
plt.pie(df_gender['Frequency'], labels=['Male','Missing','Female'],
autopct='%1.1f%%', pctdistance=0.85,
explode=explode)
# draw circle
centre_circle = plt.Circle((0, 0), 0.70, fc='white')
fig = plt.gcf()
# Adding Circle in Pie chart
fig.gca().add_artist(centre_circle)
# Adding Title of chart
plt.title('Gender proportion (with null cases)')
# Displaying Chart
plt.show()
# without null
# explosion
explode = (0.05, 0.05)
# Pie Chart
plt.pie(df_gender[~df_gender['Gender'].isnull()]['Frequency'], labels=['Male','Female'],
autopct='%1.1f%%', pctdistance=0.85, colors=['tab:blue','tab:green'],
explode=explode)
# draw circle
centre_circle = plt.Circle((0, 0), 0.70, fc='white')
fig = plt.gcf()
# Adding Circle in Pie chart
fig.gca().add_artist(centre_circle)
# Adding Title of chart
plt.title('Gender proportion')
# Displaying Chart
plt.show()
Show code cell source
# Proportion of is_architect field
df_isarch=pd.DataFrame(dict(Counter(df_daqa_dict['person']["is_architect"])).items(),
columns=["is_architect","Frequency"])
# explosion
explode = (0.05, 0.05)
# Pie Chart
plt.pie(df_isarch['Frequency'], labels=df_isarch['is_architect'],
autopct='%1.1f%%', pctdistance=0.85,
explode=explode)
# draw circle
centre_circle = plt.Circle((0, 0), 0.70, fc='white')
fig = plt.gcf()
# Adding Circle in Pie chart
fig.gca().add_artist(centre_circle)
# Adding Title of chart
plt.title('Proportion of architects in DAQA persons data')
# Displaying Chart
plt.show()
Show code cell source
# categorical associations - gender and is_architect
pd.crosstab(df_daqa_dict['person']['gender'],
df_daqa_dict['person']['is_architect'], normalize='index')\
.plot(kind='bar', rot=0)
plt.title(f'Categorical associations, Is Architect and Gender, p={str(round(chi2_contingency([[34, 85], [133, 566]])[1],2))}')
plt.show()
Show code cell source
# Proportion of architects practicing in Queensland
df_isarchfromqld=pd.DataFrame(dict(Counter(df_daqa_dict['person']["is_practiceInQueensland"])).items(),
columns=["is_practiceInQueensland","Frequency"])
# explosion
explode = (0.05, 0.05)
# Pie Chart
plt.pie(df_isarchfromqld['Frequency'],
labels=df_isarchfromqld['is_practiceInQueensland'],
autopct='%1.1f%%', pctdistance=0.85,
explode=explode)
# draw circle
centre_circle = plt.Circle((0, 0), 0.70, fc='white')
fig = plt.gcf()
# Adding Circle in Pie chart
fig.gca().add_artist(centre_circle)
# Adding Title of chart
plt.title('Proportion of persons practicing in QLD')
# Displaying Chart
plt.show()
Education experiences#
Next we analyse the educational affliations of persons in DAQA. First we clean the data by removing rows with missing data and tidying inconsistent values, and assess the summary statistics of the data.
We find that out of the 1103 persons in DAQA, only 163 person records (15%) have populated education fields. As there are 210 education records, this suggests that most persons have one completed education record. However, there are some cases where a person has four education records i.e.,
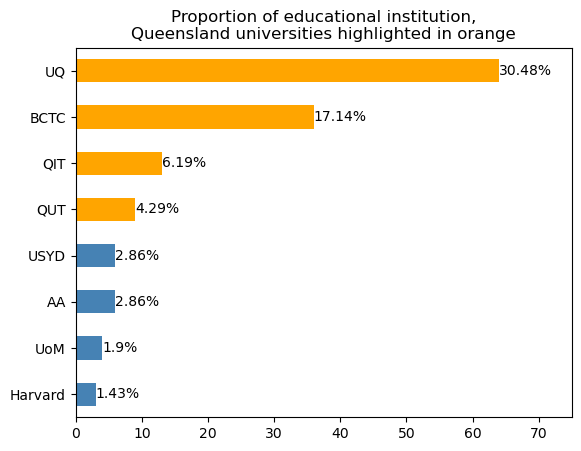
Robert Riddel.There are 39 unique education institutions in the data, with the University of Queensland being the most common with 78 occurences.
There are 10 unique education qualifications in the data, with Diploma of Architecture being the most common with 84 occurences.
Over two-thirds of education records are associated with a Queensland education institution (163 records).
Show code cell source
# inspect data
ee_df = pd.DataFrame()
for ii,ee in enumerate(df_daqa_dict['person']['education_trainings']):
if isinstance(ee, float): continue
if len(ee):
this_ee = pd.json_normalize(json.loads(ee))
this_ee['display_name'] = ast.literal_eval(df_daqa_dict['person'].iloc[ii]['display_name'])
ee_df = ee_df.append(this_ee)
# remove incomplete and remove rows with no completion dates
ee_df = ee_df[ee_df['coverage_range.date_range.date_end.year'] != 'incomplete']
ee_df = ee_df[~ee_df['coverage_range.date_range.date_end.year'].isnull()]
# remove rows with no qualification data
ee_df = ee_df[~ee_df['organization.qualification'].isnull()]
ee_df = ee_df[ee_df['organization.qualification'] != 'INCOMPLETE']
# remove rows with no school name
ee_df = ee_df[~ee_df['organization.name'].isnull()]
# remove case of honorary doctorates
ee_df = ee_df[ee_df['organization.name'] != 'QUT, UQ']
# fix missing place name
ee_df.loc[ee_df['organization.name'] == 'CAMBRIDGE','coverage_range.place'] = 'UK'
# fix anomalies
anomalies = ee_df[ee_df.display_name.str.contains('Richard Allom|Lilly Addison|Edward James Archibald Weller|Robyn Hesse|Malcolm Bunzli|Dorothy Brennan|Donald Watson|Bruce Goodsir')]['display_name'].unique()
ee_df = ee_df[~ee_df.display_name.isin(anomalies)]
Show code cell source
# clean qualification data
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['BACHELOR OF ARCHITECTURE',
'BA','B.ARCH','BArch hons']),
'BArch',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['BA SCIENCE(BOTANY)',
'BA Town Planning','BA Larch',
'BA Design Studies',
'BA Design','BA Design',
'BAppSci','BA (?) Town Planning']),
'Bachelor (Other)',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['Diploma','DIPLOMA',
'DIP Arch','DIPLOMA OF ARCHITECTURE',
'DipA']),
'DipArch',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['GradDip Uni Planning',
'GradDip Project Management',
'Grad Dip Town Planning',
'Gdip Urban Planning',
'GradDip landscape','Grad Dip Landscape']),
'GDip (Other)',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['Grad Dip']),
'GDipArch',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['M.A.ARCHITECTURE']),
'MArch',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['MA Town Planning','MBA',
'MA App Sc','MA Education',
'MArts','MArts (Urban design)',
'Masters in Art','M.Litt',
'MA Urban Studies']),
'Masters (Other)',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['PhD (hon)','PHD',]),
'PhD',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['CERT','certificate',
'CERTIFICATE OF ARCHITECTURE']),
'CertArch',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['CERTIFICATE OF TOWN PLANNING',
'Cert Art&Design']),
'Cert (Other)',ee_df['organization.qualification'])
ee_df['organization.qualification'] = np.where(ee_df['organization.qualification']
.isin(['CERTIFICATE OF TOWN PLANNING',
'Cert Art&Design']),
'Cert (Other)',ee_df['organization.qualification'])
topquals = pd.DataFrame(ee_df['organization.qualification'].value_counts())\
.reset_index()\
.rename({'index':'Qualification','organization.qualification':'Frequency'}, axis=1)\
.head(10)['Qualification']\
.values
ee_df['organization.qualification'] = np.where(~ee_df['organization.qualification'].isin(topquals),
'Unknown',ee_df['organization.qualification'])
ee_df['organization.qualification2'] = ee_df['organization.qualification']
ee_df['organization.qualification2'] = np.where(ee_df['organization.qualification'].str.contains('B'),
'Bachelor',ee_df['organization.qualification2'])
ee_df['organization.qualification2'] = np.where(ee_df['organization.qualification'].str.contains('M'),
'Masters',ee_df['organization.qualification2'])
ee_df['organization.qualification2'] = np.where(ee_df['organization.qualification'].str.contains('GDip'),
'Graduate Diploma',ee_df['organization.qualification2'])
ee_df['organization.qualification2'] = np.where(ee_df['organization.qualification'].str.contains('Cert'),
'Certificate',ee_df['organization.qualification2'])
ee_df['organization.qualification2'] = np.where(ee_df['organization.qualification']=='DipArch',
'Diploma',ee_df['organization.qualification2'])
Show code cell source
# clean place/school data
ee_df['coverage_range.place'] = np.where(((ee_df['coverage_range.place'] == 'VIC') &
(ee_df['organization.name'] == 'UQ')) |
((ee_df['coverage_range.place'] == 'MELBOURNE') &
(ee_df['organization.name'] == 'UQ')) |
(ee_df['coverage_range.place'] == 'Qld') |
(ee_df['coverage_range.place'] == 'Qld') |
(ee_df['coverage_range.place'] == 'qld') |
(ee_df['coverage_range.place'] == 'UNI'),
'QLD',ee_df['coverage_range.place'])
ee_df['coverage_range.place'] = np.where((ee_df['coverage_range.place'] == 'MELBOURNE'),
'VIC',ee_df['coverage_range.place'])
ee_df['coverage_range.place'] = np.where((ee_df['coverage_range.place'] == 'SYDNEY') |
(ee_df['coverage_range.place'] == 'Colle'),
'NSW',ee_df['coverage_range.place'])
ee_df['coverage_range.place'] = np.where((ee_df['coverage_range.place'] == 'USA') |
(ee_df['coverage_range.place'] == 'New York') |
(ee_df['coverage_range.place'] == 'CANADA'),
'USA',ee_df['coverage_range.place'])
ee_df['coverage_range.place'] = np.where((ee_df['coverage_range.place'] == 'AUCKLAND'),
'NZ',ee_df['coverage_range.place'])
ee_df['coverage_range.place'] = np.where((ee_df['coverage_range.place'] == 'Scotland'),
'SCOTLAND',ee_df['coverage_range.place'])
ee_df['coverage_range.place'] = np.where((ee_df['coverage_range.place'] == 'LONDON') |
(ee_df['coverage_range.place'] == 'SCOTLAND') |
(ee_df['coverage_range.place'] == 'Indep') |
(ee_df['coverage_range.place'] == 'England'),
'UK',ee_df['coverage_range.place'])
ee_df['coverage_range.place'] = np.where((ee_df['coverage_range.place'] == 'Vienna, Austria') |
(ee_df['coverage_range.place'] == 'VIENNA') |
(ee_df['coverage_range.place'] == 'Vienna') |
(ee_df['coverage_range.place'] == 'Vienna Austria') |
(ee_df['coverage_range.place'] == 'Vienna, AUSTRIA'),
'Other (Europe)',ee_df['coverage_range.place'])
ee_df['coverage_range.place'] = np.where((ee_df['coverage_range.place'] == 'Norway') |
(ee_df['coverage_range.place'] == 'MILAN') |
(ee_df['coverage_range.place'] == 'Rome') |
(ee_df['coverage_range.place'] == 'SLOVAKIA') |
(ee_df['coverage_range.place'] == 'Hungary') |
(ee_df['coverage_range.place'] == 'Cech') |
(ee_df['coverage_range.place'] == 'GERMANY'),
'Other (Europe)',ee_df['coverage_range.place'])
ee_df['coverage_range.place'] = np.where((ee_df['coverage_range.place'] == 'GUADALAJARA') |
(ee_df['coverage_range.place'] == 'SOUTH AFRICA') |
(ee_df['coverage_range.place'] == 'INDIA'),
'Other (Rest of World)',ee_df['coverage_range.place'])
ee_df['organization.name'] = np.where((ee_df['organization.name'] == 'UoM'), #data entry error
'UQ',ee_df['organization.name'])
ee_df['organization.name'] = np.where((ee_df['organization.name'] == 'BCTC/UQ') |
(ee_df['organization.name'] == 'BCTC?UQ') |
(ee_df['organization.name'] == 'CTC') |
(ee_df['organization.name'] == 'BRISBANE CENTRAL TECHNICAL COLLEGE'),
'BCTC',ee_df['organization.name'])
ee_df['organization.name'] = np.where((ee_df['organization.name'] == 'Sydney') |
(ee_df['organization.name'] == 'SYDNEY UNI') |
(ee_df['organization.name'] == 'Sydney University'),
'USYD',ee_df['organization.name'])
ee_df['organization.name'] = np.where((ee_df['organization.name'] == 'Melb') |
(ee_df['organization.name'] == 'Melbourne') |
(ee_df['organization.name'] == 'UNI OF MELBOURNE') |
(ee_df['organization.name'] == 'MELBOURNE'),
'UoM',ee_df['organization.name'])
ee_df['coverage_range.place'] = np.where((ee_df['organization.name'] == 'UoM'),
'VIC',ee_df['coverage_range.place'])
ee_df['organization.name'] = np.where((ee_df['organization.name'] == 'SYDNEY TECHNICAL COLLEGE'),
'STC',ee_df['organization.name'])
ee_df['organization.name'] = np.where((ee_df['organization.name'] == 'EAST SYDNEY TECH COLLEGE AND TOWN PLANNING'),
'ESTC',ee_df['organization.name'])
ee_df['organization.name'] = np.where((ee_df['organization.name'] == 'Melb TC'),
'MTC',ee_df['organization.name'])
ee_df['organization.name'] = np.where((ee_df['organization.name'] == 'HAVARD GRAD SCH OF DESIGN') |
(ee_df['organization.name'] == 'HAVARD UNI'),
'Harvard',ee_df['organization.name'])
ee_df['organization.name'] = np.where((ee_df['organization.name'] == 'articled') |
(ee_df['organization.name'] == 'articles') |
(ee_df['organization.name'] == 'Articled Pup') |
(ee_df['organization.name'] == 'Articled'),
'Articled',ee_df['organization.name'])
# Summary statistics
# display(HTML(ee_df.describe().to_html()))
print('Summary statistics:')
display(ee_df.drop(['organization.type','coverage_range.date_range.date_end.year','organization.qualification2'],axis=1).describe())
Summary statistics:
| organization.name | organization.qualification | coverage_range.place | display_name | |
|---|---|---|---|---|
| count | 210 | 210 | 210 | 210 |
| unique | 39 | 10 | 8 | 163 |
| top | UQ | DipArch | QLD | Robert Riddel |
| freq | 78 | 84 | 153 | 4 |
How many qualifications do persons in the the DAQA hold?#
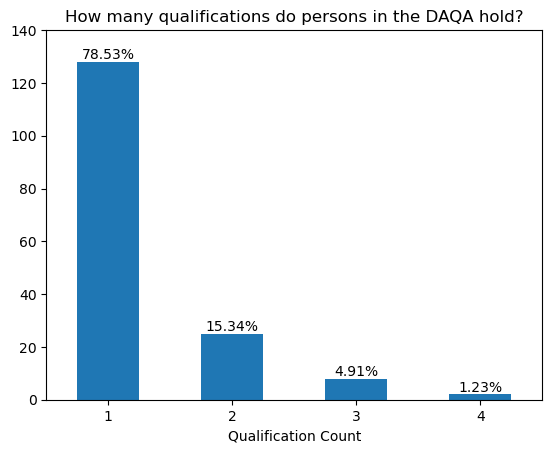
Upon further inspection, we find that most persons in DAQA have one qualification (79%), with 15% having two qualifications and 6% having three or more qualifications. Below we list the persons with three or more qualifications. We find that most of these persons have a PhD.
Person records with three education qualifications:
Balwant Saini (BArch, BArch, PhD)
Blair Wilson (BArch, DipArch, Graduate Diploma)
Gordon Holden (DipArch, Masters ,PhD)
Graham de Gruchy (BArch, Masters ,PhD)
Janet Conrad (BArch, Bachelor, Masters)
Karl Langer (CertArch, DipArch, PhD)
Peter Skinner (Bachelor, BArch, MArch)
Steven Szokolay (BArch, MArch, PhD)
Person records with four education qualifications:
Barbara van den Broek (DipArch, Graduate Diploma, Graduate Diploma, Masters)
Robert Riddel (DipArch, Masters, DipArch, PhD)
Show code cell source
## bar chart of number of qualifications
df_persons_with_qual = pd.DataFrame(ee_df['display_name'].value_counts())\
.reset_index()\
.rename({'index':'Person',
'display_name':'Frequency'}, axis=1)
df = pd.DataFrame(df_persons_with_qual['Frequency']\
.value_counts())\
.reset_index()\
.rename({'index':'Qualification Count'}, axis=1)
labels = ((df['Frequency']/df_persons_with_qual.shape[0])*100)\
.round(2).astype('str') + '%'
ax = df.plot.bar(x='Qualification Count', y='Frequency',rot=0)
# add bar labels
[ax.bar_label(container, labels=labels)
for container in ax.containers]
# remove legend and y-axis title
ax.legend().set_visible(False)
plt.ylabel(None)
plt.title('How many qualifications do persons in the DAQA hold?')
plt.ylim([0, 140])
plt.show()
# use to check people with multiple qualifications
# ee_df[(ee_df['display_name']\
# .isin(df_persons_with_qual[df_persons_with_qual.Frequency > 2]['Person']\
# .values))]\
# .sort_values(['display_name','coverage_range.date_range.date_end'])
Education qualification types#
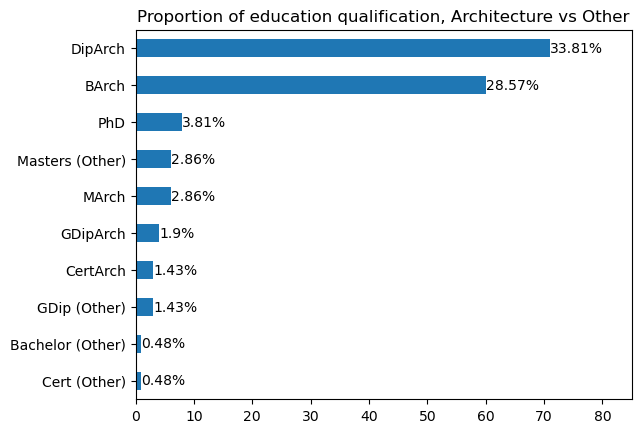
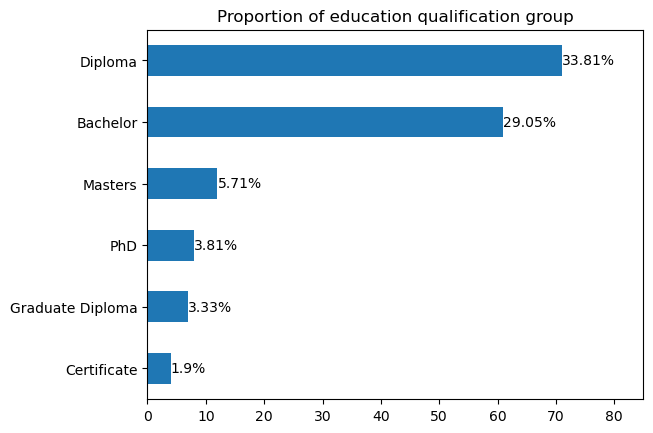
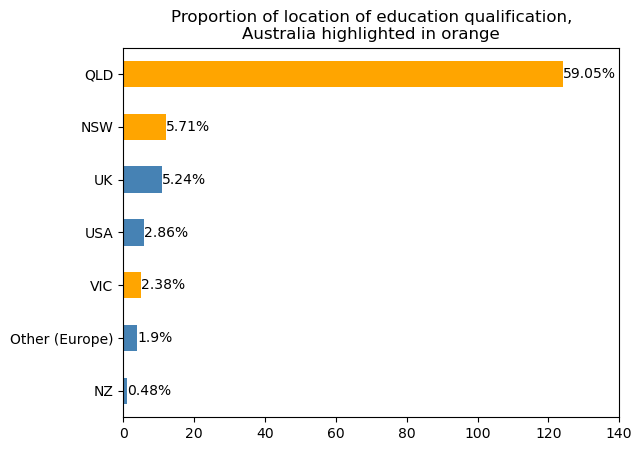
Firstly, we plot the number of education records for each qualification type. We further aggregate the education qualifications into six broad categories. We find that most persons in DAQA have a Diploma (34% of records), followed by a Bachelor (29% of records). Next, we inspect the distribution of the location of the qualifications. Beyond Queensland, other locations with a high number of education records include New South Wales, Victoria, the United Kingdom and the United States. The last bar chart reveals the number of education records by education institution. We only show the top eight universities, with the University of Queensland being the most common.
It should be noted that BCTC, QIT and QUT refer to the same institution, but have changed names over time. AA refers to the Architectural Association School of Architecture (based in the UK) and STC refers to the Sydney Technical College.
Show code cell source
# keep last education record
ee_df_last = ee_df\
.sort_values(['coverage_range.date_range.date_end.year','display_name'])\
.drop_duplicates(subset='display_name', keep="last")
# bar chart of qualification
ee_freq = pd.DataFrame(ee_df_last['organization.qualification'].value_counts())
df = ee_freq\
.reset_index()\
.rename({'index':'Qualification',
'organization.qualification':'Frequency'}, axis=1)\
.sort_values('Frequency')
df = df[~df['Qualification'].isin(['Unknown'])]
# df['Colour'] = np.where(df['Place'].isin(['QLD','VIC','NSW','TAS']),'orange','steelblue')
labels = ((df['Frequency']/ee_df.shape[0])*100)\
.round(2).astype('str') + '%'
ax = df.plot.barh(x='Qualification', y='Frequency',rot=0)
# add bar labels
[ax.bar_label(container, labels=labels)
for container in ax.containers]
# remove legend and y-axis title
ax.legend().set_visible(False)
plt.ylabel(None)
plt.title('Proportion of education qualification, Architecture vs Other')
plt.xlim([0, 85])
plt.show()
Show code cell source
# bar chart of qualification type
ee_freq = pd.DataFrame(ee_df_last['organization.qualification2'].value_counts())
df = ee_freq\
.reset_index()\
.rename({'index':'Qualification Type',
'organization.qualification2':'Frequency'}, axis=1)\
.sort_values('Frequency')
df = df[~df['Qualification Type'].isin(['Unknown'])]
labels = ((df['Frequency']/ee_df.shape[0])*100)\
.round(2).astype('str') + '%'
ax = df.plot.barh(x='Qualification Type', y='Frequency',rot=0)
# add bar labels
[ax.bar_label(container, labels=labels)
for container in ax.containers]
# remove legend and y-axis title
ax.legend().set_visible(False)
plt.ylabel(None)
plt.title('Proportion of education qualification group')
plt.xlim([0, 85])
plt.show()
Show code cell source
# bar chart of location of education institution
ee_freq = pd.DataFrame(ee_df_last['coverage_range.place'].value_counts())
df = ee_freq\
.reset_index()\
.rename({'index':'Place',
'coverage_range.place':'Frequency'}, axis=1)\
.sort_values('Frequency')
df['Colour'] = np.where(df['Place'].isin(['QLD','VIC','NSW','TAS']),'orange','steelblue')
labels = ((df['Frequency']/ee_df.shape[0])*100)\
.round(2).astype('str') + '%'
ax = df.plot.barh(x='Place', y='Frequency', color=df['Colour'].values ,rot=0)
# add bar labels
[ax.bar_label(container, labels=labels)
for container in ax.containers]
# remove legend and y-axis title
ax.legend().set_visible(False)
plt.ylabel(None)
plt.title('Proportion of location of education qualification,\nAustralia highlighted in orange')
plt.xlim([0, 140])
plt.show()
Show code cell source
# bar chart of education institution
ee_freq = pd.DataFrame(ee_df_last['organization.name'].value_counts()).head(8)
df = ee_freq\
.reset_index()\
.rename({'index':'School Name',
'organization.name':'Frequency'}, axis=1)\
.sort_values('Frequency')
# df = df[~df['School Name'].isin(['Articled','NOT IN DAQA'])]
labels = ((df['Frequency']/ee_df.shape[0])*100)\
.round(2).astype('str') + '%'
df['Colour'] = np.where(df['School Name']\
.isin(['UQ','BCTC','QIT','QUT']),
'orange','steelblue')
ax = df.plot.barh(x='School Name', y='Frequency',
color=df['Colour'].values, rot=0)
# add bar labels
[ax.bar_label(container, labels=labels)
for container in ax.containers]
# remove legend
ax.legend().set_visible(False)
plt.ylabel(None)
plt.title('Proportion of educational institution,\nQueensland universities highlighted in orange')
plt.xlim([0, 75])
plt.show()
Education over time#
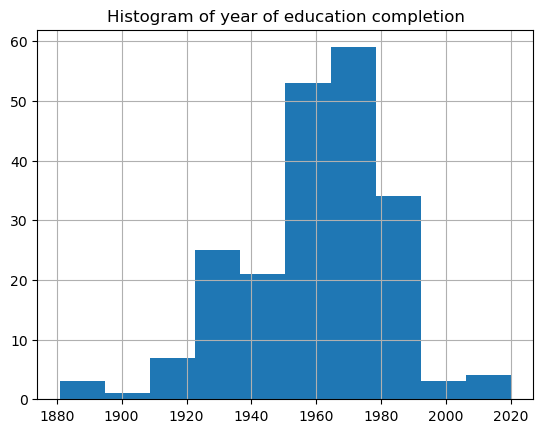
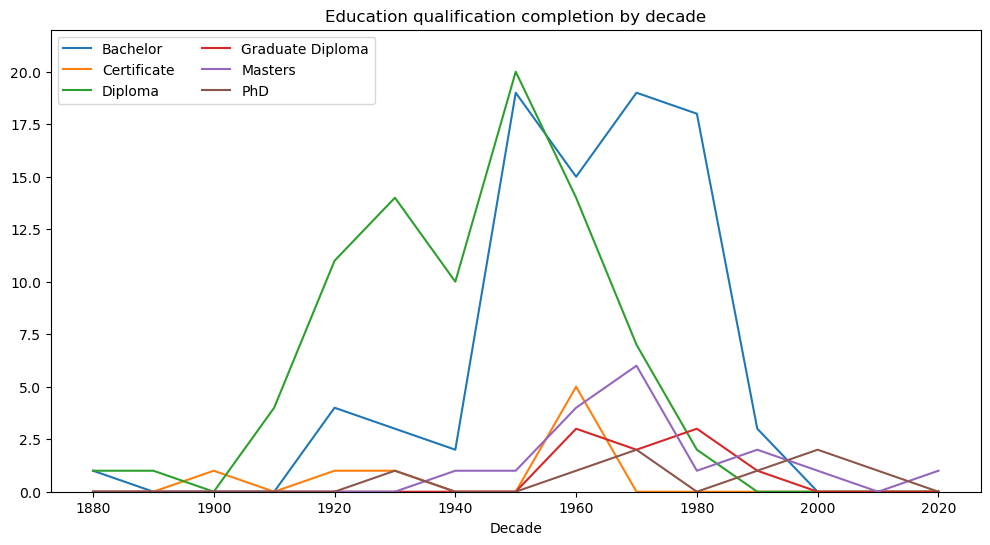
We continue the analysis by visualising education records with respect to year. The histogram below highlights that most education records are from the 1960s and 1970s. We also plot the number of education records by year and education qualification.
Show code cell source
## Histogram of year of education completion
ee_df['coverage_range.date_range.date_end.year'] = ee_df['coverage_range.date_range.date_end.year']\
.apply(lambda x: x[0:4])\
.astype(int)
ee_df['coverage_range.date_range.date_end.year'].hist()
plt.title('Histogram of year of education completion')
plt.show()
Show code cell source
## line chart by decade of education completion
ee_df['date_end_decade'] = [ int(np.floor(int(year)/10) * 10)
for year in np.array(ee_df['coverage_range.date_range.date_end.year'])]
ax = pd.crosstab(ee_df['date_end_decade'],
ee_df['organization.qualification2'])\
.plot(rot=0, figsize=(12,6))
# adjust legend
ax.legend(loc="upper left", ncol=2)
plt.xlabel('Decade')
plt.ylim([0, 22])
plt.title('Education qualification completion by decade')
plt.show()
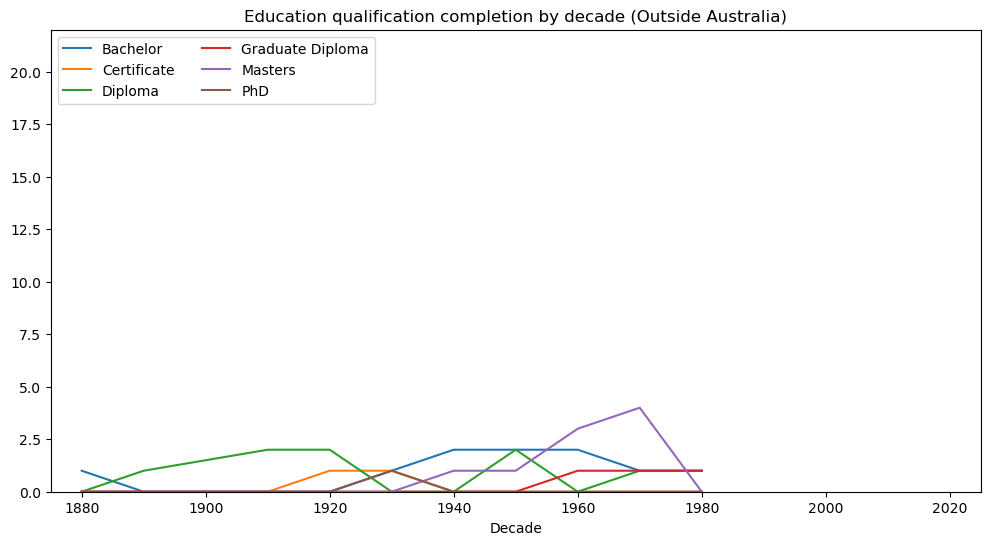
Show code cell source
# line chart by decade of education completion (outside AUS)
ee_df_notqld = ee_df[~ee_df['coverage_range.place'].isin(['QLD','TAS','NSW','VIC'])]
ax = pd.crosstab(ee_df_notqld['date_end_decade'],
ee_df_notqld['organization.qualification2'])\
.plot(rot=0, figsize=(12,6))
# adjust legend
ax.legend(loc="upper left", ncol=2)
plt.xlabel('Decade')
plt.xlim([1875, 2025])
plt.ylim([0, 22])
plt.title('Education qualification completion by decade (Outside Australia)')
plt.show()
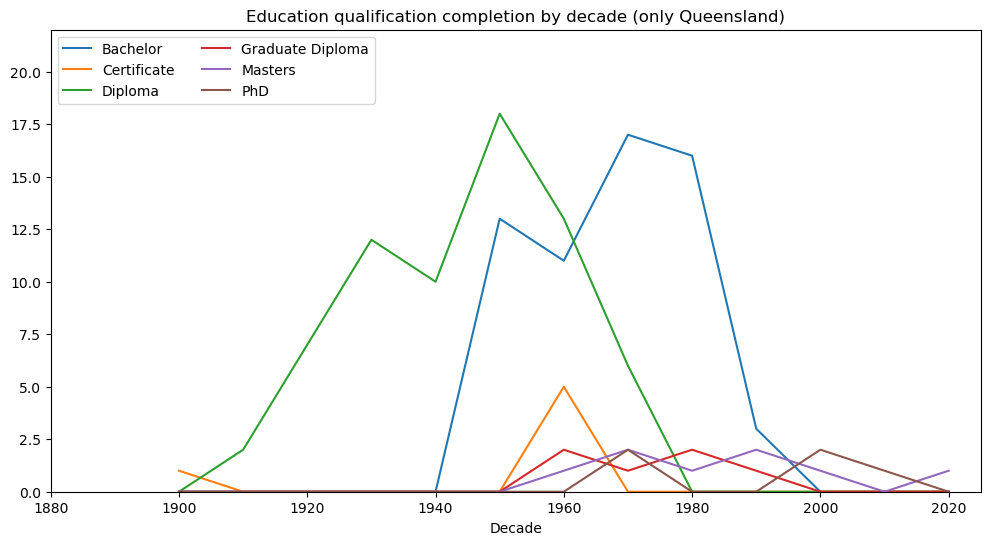
Education over time (only Queensland)#
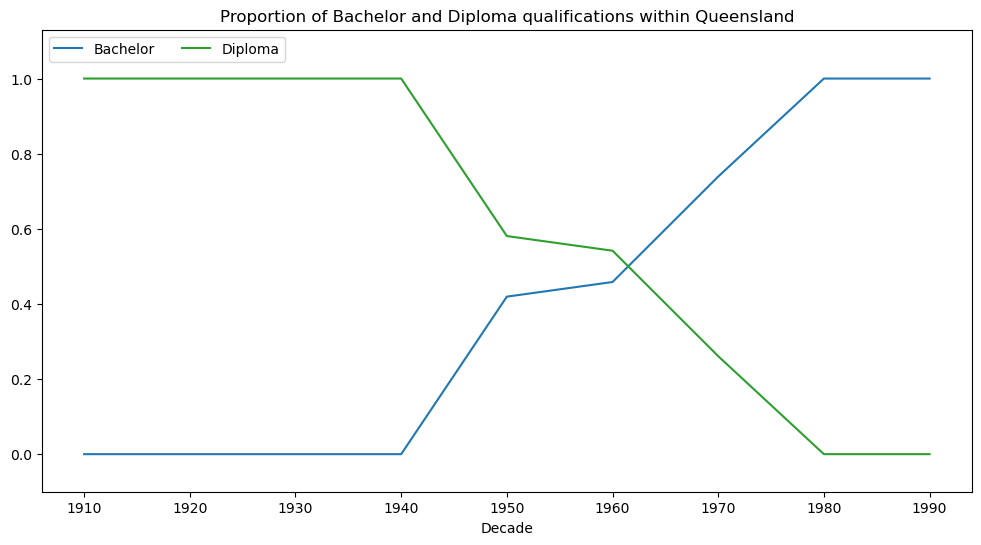
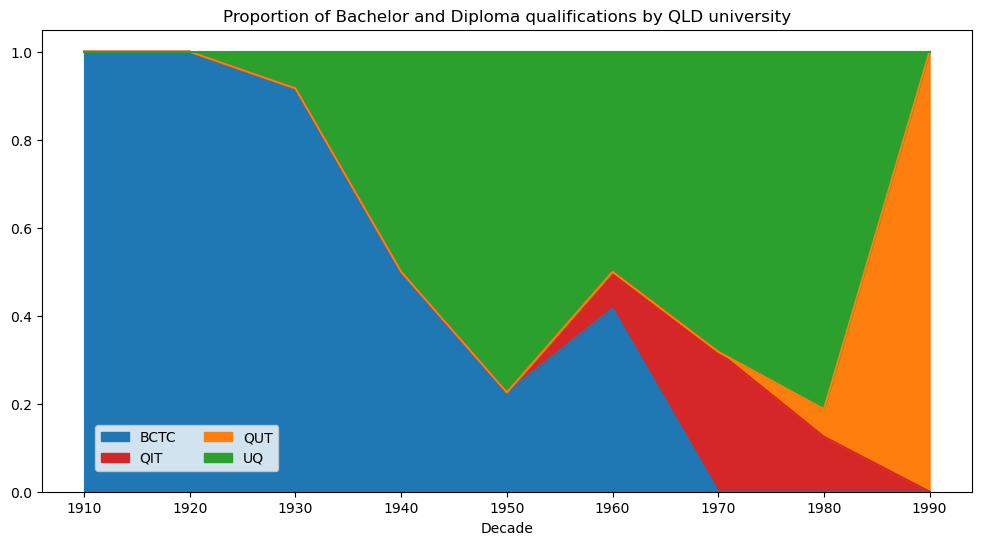
Next we focus solely on education records from Queensland. A shift in the adoption of education qualification type is observed around the 1960s. This shift is particularly emphasised in the second visualisation where proportions of Bachelor and Diploma records are plotted. For further context, we also provide visualisations with respect to education institution and education qualification.
Show code cell source
# line chart by decade of education completion (only queensland)
ee_df_qld = ee_df[ee_df['coverage_range.place'].isin(['QLD'])]
ax = pd.crosstab(ee_df_qld['date_end_decade'],
ee_df_qld['organization.qualification2'])\
.plot(rot=0, figsize=(12,6))
# adjust legend
ax.legend(loc="upper left", ncol=2)
plt.xlabel('Decade')
plt.xlim([1880, 2025])
plt.ylim([0, 22])
plt.title('Education qualification completion by decade (only Queensland)')
plt.show()
Show code cell source
# bachelor/diploma proportion over decade (only queensland)
ee_df2 = ee_df[(ee_df['organization.qualification2'].isin(['Bachelor','Diploma'])) &
(ee_df['coverage_range.place'].isin(['QLD']))]
ax = pd.crosstab(ee_df2['date_end_decade'],
ee_df2['organization.qualification2'], normalize='index')\
.plot(rot=0, figsize=(12,6), color=['tab:blue','tab:green'])
# adjust legend
ax.legend(loc="upper left", ncol=2)
plt.xlabel('Decade')
plt.ylim([-0.1, 1.13])
plt.title('Proportion of Bachelor and Diploma qualifications within Queensland')
plt.show()
Show code cell source
# bachelor/diploma over decade by qld institutions
ee_df2 = ee_df[(ee_df['organization.qualification2'].isin(['Bachelor','Diploma'])) &
(ee_df['coverage_range.place'].isin(['QLD'])) &
(~ee_df['organization.name'].isin(['Townsville TC']))]
ax = pd.crosstab(ee_df2['date_end_decade'],
ee_df2['organization.name'],normalize='index')\
.plot(kind='area',stacked=True,rot=0, figsize=(12,6),
color=['tab:blue','tab:red',
'tab:orange','tab:green'])
# adjust legend
ax.legend(loc="lower left", ncol=2, bbox_to_anchor=(0.05, 0.03))
plt.xlabel('Decade')
plt.title('Proportion of Bachelor and Diploma qualifications by QLD university')
plt.show()
Show code cell source
# bachelor/diploma over decade by qld institutions, summarised
ee_df2['main_qld_unis'] = np.where(ee_df2['organization.name'].isin(['BCTC','QUT','QIT']),
'BCTC/QIT/QUT', ee_df2['organization.name'])
ee_df2['main_qld_unis'] = ee_df2['main_qld_unis'] + ' : ' + ee_df2['organization.qualification2']
ax = pd.crosstab(ee_df2['date_end_decade'],
ee_df2['main_qld_unis'])\
.plot(kind='bar',stacked=True,rot=0, figsize=(12,6))
# adjust legend
ax.legend(loc="upper left", ncol=2)
plt.xlabel('Decade')
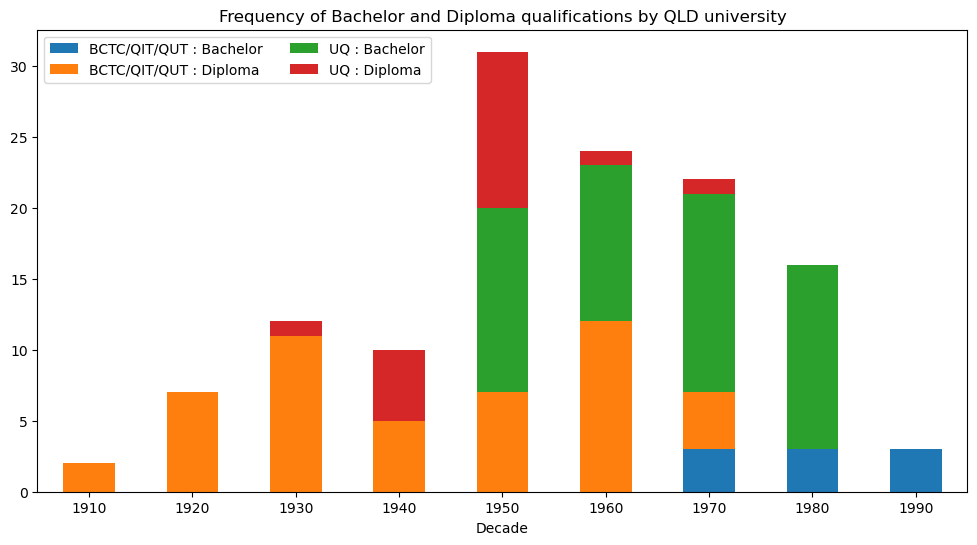
plt.title('Frequency of Bachelor and Diploma qualifications by QLD university')
plt.show()
DAQA Organisations#
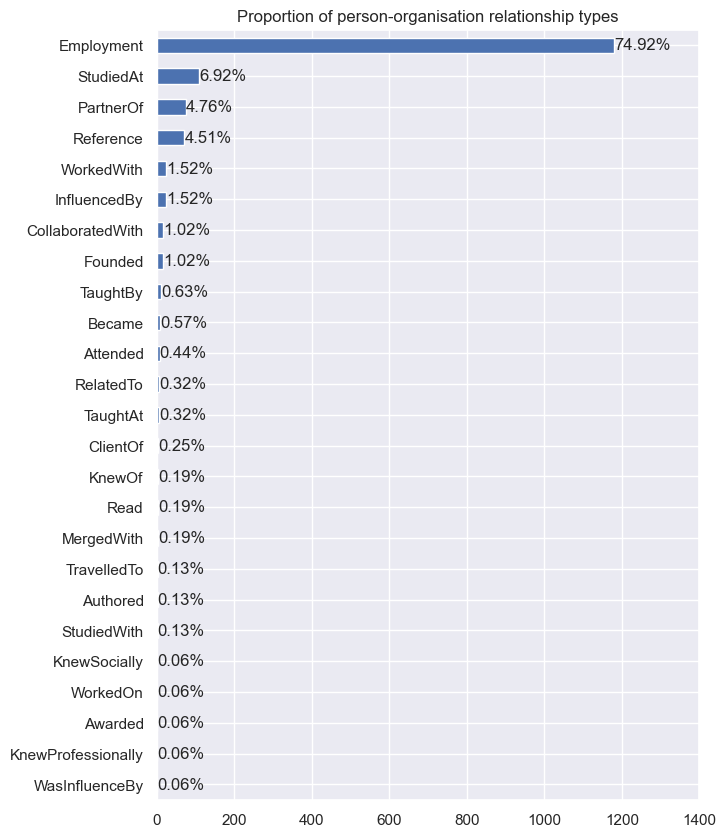
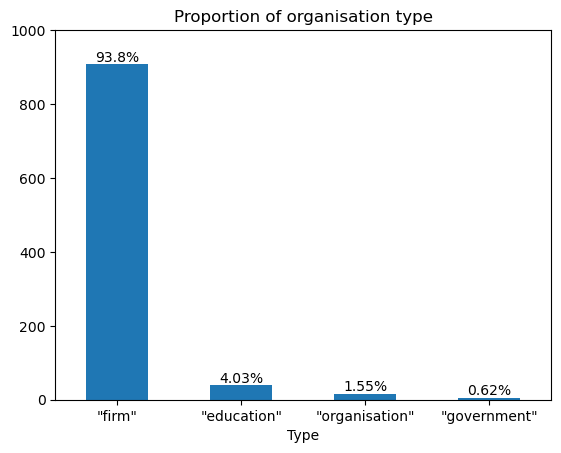
There are 967 organisation records in DAQA. The bar chart below shows the proportion of organisations by type, with the majority being architectural firms. We also plot the number of types of person-organisation relationships. We find that three-quarters of these relationships are employment-related.
Show code cell source
# bar chart of organisation type
type_freq = pd.DataFrame(df_daqa_dict['organization']['_class_ori'].value_counts())
print(type_freq.T,'\n')
df = type_freq\
.reset_index()\
.rename({'index':'Type',
'_class_ori':'Frequency'}, axis=1)
labels = ((df['Frequency']/df_daqa_dict['organization'].shape[0])*100)\
.round(2).astype('str') + '%'
ax = df.plot.bar(x='Type', y='Frequency', rot=0)
# add bar labels
[ax.bar_label(container, labels=labels)
for container in ax.containers]
# remove legend
ax.legend().set_visible(False)
# increase y-axuis limit
ax.set_ylim(0, 1000)
plt.title('Proportion of organisation type')
plt.show()
"firm" "education" "organisation" "government"
_class_ori 907 39 15 6
Show code cell source
daqa_person_orgs = []
for idx, row in df_daqa_dict['person'].iterrows():
try: daqa_person_orgs.append(pd.json_normalize(json.loads(row['related_organizations'])))
except: continue
# turn list to dataframe
daqa_person_orgs = pd.concat(daqa_person_orgs)
print(f'There are {daqa_person_orgs.shape[0]} person-organisation relation records.')
# bar chart of predicate type for person/org relationships
df = pd.DataFrame(
daqa_person_orgs['predicate.term']
.value_counts()\
.reset_index())\
.rename({'index':'Predicate',
'predicate.term':'Frequency'}, axis=1)\
.sort_values('Frequency')
# ee_freq = pd.DataFrame(ee_df_last['school.qualification2'].value_counts())
# print(ee_freq.T,'\n')
labels = ((df['Frequency']/daqa_person_orgs.shape[0])*100)\
.round(2).astype('str') + '%'
sns.set(rc={'figure.figsize':(7,10)})
ax = df.plot.barh(x='Predicate', y='Frequency',rot=0)
# add bar labels
[ax.bar_label(container, labels=labels)
for container in ax.containers]
# remove legend and y-axis title
ax.legend().set_visible(False)
plt.ylabel(None)
plt.xlim([0, 1400])
plt.title('Proportion of person-organisation relationship types')
plt.show()
There are 1575 person-organisation relation records.